Case Study
How I Designed a Low-Friction Referral Monitoring Platform for Affiliate Marketing

Designing a low-friction, scalable solution for solving regulatory issues in affiliate marketing
This article explains how I designed a low-friction solution for a client to address an urgent compliance problem.
The problem
A client I had been supporting was approached by one of their clients. The problem was that they were facing regulatory pressure due to ads and product links being placed with inconsistent messaging in unknown locations. Operating licences in certain territories were at risk, and if they were lost, the business would suffer irreversible damage.
The client needed to identify where the traffic was coming from and who was responsible for it, and then validate that consumer-focused messaging was within the marketing guidelines.
The problem I was asked to solve was whether we could identify websites driving traffic to the destination website. If we could do that, the websites could be validated for their marketing compliance. My role was to design a quick-to-deploy, scalable, and low-cost solution to solve the problem as quickly and accurately as possible.
The solution
We needed to find which websites were linking to the client's website. This is all. Once that link was established, the linking website could be analysed for problematic messaging.
A few ideas were instantly proposed.
Searching the internet
The initial idea was to search the internet, but due to time constraints, this wasn’t possible. This is a high work task with slow results. You see some websites and run some automated Google searches, then start crawling.
This is slow, intensive, requires a lot of management and produces slow results.
Google Analytics and similar tools
This was my first suggestion: we could use an API to pull the session data. But there are a couple of issues here.
Google Analytics is complex, and reporting is complicated.
Data thresholds mean we are likely to gain visibility of all data.
The client we were solving this problem for didn’t use Google Analytics and had no easy access to this in their own reporting tools.
Log processing
Parse and process web logs. A simple idea, but with too much friction: it would require involvement of security and technical teams, probably hundreds of gigabytes of data, and a complicated process. Clusters of web servers, distributed logging.
How far do you go back? Do you build a real-time stream analysis platform? How do you protect private requests or pages? Do the logs actually contain all the required data?
The more I dug into log processing, the more friction I encountered.
A low-friction solution was needed - JavaScript
There had to be another way to track traffic more quickly without involving multiple departments.
I wondered if we could build a low-profile collector, like Google Analytics, to capture the referrer in real time on the client website and send that information directly to us. It would need to be unobtrusive and transparent to the user.
If this were possible, it would give us results almost instantly, be quick to deploy, and eliminate the need to involve the client with integration.
A small JavaScript snippet on the inbound website could capture the HTTP Referer and the target page, then send them to our analysis process. It would need to support a high volume of traffic, with heavy spikes.
The tool isn’t tracking users' movements, so there is no need for cookies, and the system doesn’t need any user data.
I built a demonstrator and then sent it off for approval. This was the solution. The reasoning and trade-offs were acceptable to the clients.
After discussions with the clients, it was established that the websites were not actively driving traffic, which was of lower priority. The benefit of using client-side logging was that the most active websites driving traffic would be analysed first. This was actually a benefit to the client.
Option comparison
| Method | Pros | Cons |
|---|---|---|
| Searching Internet | Discover websites even if they drive no traffic | Slow Expensive High work to low signal |
| Google Analytics | Has the data Already deployed Read only access |
Data thresholds may suppress data Security teams and API access require teams to review and grant Requires tool to already be in use |
| Log Processing | Can be configured to log the referrer Easy to process |
Security teams would need to review and separate out logs and grant access to specific entries Timeframes are hard to determine |
| Custom JavaScript | Quick to deploy, client only deploys JS to web site, nothing else Easy to review with security teams Easy to disable & remove, no residue left over Protected areas can omit the Javascript easily |
Risk interruption of user experience Only discovers websites driving traffic |
A quick note on Referrers
The HTTP referrer used to include the entire URL, but with browser privacy changes, it is now more common for the browser to send only the domain. Once the referral domain is received, another process would be required to detect the content on that website, but that is outside the scope of this article.
The client accepted that this would not provide full discoverability for all websites because of redirect links that anonymise traffic and browser methods like rel="noreferrer", but it would capture the vast majority.
The technical solution
Some of the websites that will use this platform see hundreds of thousands of page views per day. There needed to be a scalable way to receive the data, and the data processing needs to be decoupled from the receiving endpoint.
There are many ways to design this. I could have developed my own receiving API and cached the data, and offloaded it in batches. I could have used a lambda to process the data, but there were technical and cost considerations.
The solution needed to meet the following criteria, which impacted the design decision.
- It did not require real-time data processing; batching was acceptable.
- It needs to tolerate bursts of traffic.
- The client-side code had to minimise any impact on the user experience.
- The system needed a small operational footprint for management.
- It needed to be fault-tolerant and resilient.
- Avoid collecting any non-essential data.
Considerations
Scalability
Building a custom solution would require verifying scalability and the cost point. It would also require its own infrastructure. EC2 & ALB? Fargate? That’s a lot of extra problems to solve in order to solve the core problem.
Privacy
There is no need to track users with this solution. Introducing cookies, if users make repeat visits, etc., would start to involve other departments. Cookie policies would need updating, and the solution could become more complicated. To solve the immediate problem, there is no need to track or identify users.
The remote IP address is recorded, but not for user monitoring or tracking. It is for identifying what regulations apply in certain jurisdictions.
Resiliancy
Building a dedicated API and data handling process is unproven; it would require significant testing. Would an ALB & EC2 combo be resilient? What would I need to do to prove its capability and resilience?
Any rejections of data should not impact the user experience - they don’t. sendBeacon does not pass responses back.
The system should keep on accepting requests even during traffic spikes - it does, the ceiling of requests is significantly higher than any website it is enabled on.
The system needed to be resilient; the collection process sits close to end users, and disruptions would affect sales and conversions. Not an option. The receiving endpoint supports bursty traffic but also disconnects processing from collection. This is why, in this instance, AWS managed services came out as the best option; they are designed to provide high availability, durability, and elasticity.
Cost
A custom solution could have been built, but it would not have been cost-effective. API Gateway, Kinesis, Firehose, and a processor via Fargate are more cost-effective. The custom solution would not have produced any different outcome or added any benefit that could not be achieved with the existing resources available.
These considerations also would have required time, something the client didn’t have - they were facing pressure now. We needed something “off the shelf”.
There is a subtle detail to the cost. I worked to produce a system that was as low-cost as possible. The business with the regulatory issues had a high motivation to solve a problem, so the budget was made available. A long-term thought I had was to look at what happens after the problem is solved. Would the client cancel? Would the product evolve? Once the initial problem is solved, if the product is low-cost, it could be maintained as a continuous monitoring product, enabling my client to compete effectively on price and shift the focus of the solution from problem-solving to problem-prevention. Safety glasses are always cheaper than eye surgery.
Success criteria
What would success look like for everyone? There needs to be a definition of what success looks like.
- Identify websites generating traffic to the client's destination site.
- No impact on the users following links to the destination site.
- Minimal tool setup and deployment required for the client.
- Collect minimum data to avoid issues like GDPR.
- A scalable multi-tenant option for multi-user or website use.
- Supportable by staff to review and retrieve data.
- Commercially viable with low technology cost.
Building the solution
After reviewing the options, I decided the best fit was to connect the AWS API Gateway to AWS Kinesis. API Gateway can handle thousands of requests under its default quota. The websites originally intended for this question are getting about 10-20 million visitors a month. Plenty of room.
Kinesis would receive the data, but then we needed to get it out of there. AWS Data Firehose was my selected choice. At the point we were doing this, we hadn’t yet decided on the best way to report this data to the client, or how to process it, so my focus was on storing the raw data. It keeps everything decoupled, but it also means we can collect data while deciding on the output.
Firehose retrieved the data from Kinesis and saved it to an S3 bucket. We then used SNS on the S3 bucket to generate a message in SQS. Stream naming conventions in Kinesis and Firehose allowed us to trace the origins of the files.
This approach created a burstable, fault-tolerant and highly scalable solution for the client. The endpoint for receiving the data, the point at which it was stored in an S3 bucket, and the entire solution were built on AWS Cloud. This tooling is scalable, fault-tolerant, more cost-effective than ALB-type solutions and secure.
The client side makes me anxious
The problem with JavaScript, in this context at least, is that it touches something physical. The code executes on a device I have no control over. This was a concern because I was asking the client to add a snippet of front-end JavaScript to their website to collect this data.
That code would execute on their customers' Android & iPhones, iPads and laptops, all of varying ages and capabilities. Impacting device performance would have been detrimental to the client’s business.
Some time was spent here thinking about this and assessing the risks. Luckily, sendBeacon was created for this kind of thing. It is a browser method with lower priority that sends a request asynchronously; you don’t get a response, but that’s fine, we don’t need it.
It has payload limits, that’s fine, we need to only send a URL.
More importantly, it doesn’t delay the unload event. We only really need to identify a website once, so if we don’t get it on one page view, we might on the next. So this was stacking up perfectly for transmitting the data entirely without impacting the user agent. It did, however, require me to support HTTP POST; that’s fine, an API gateway is easy enough to handle that.
One small quirk, by default, sendBeacon sends only in text/plain. I could have used a blob, but I didn’t want to create a scenario where I needed a client to change something once the code was delivered or risk problems, so I wanted to produce as little code as possible. Equally, any enterprise-level security teams would want to pay attention to it, so using that as a constraint, I would just reduce the time required for everything if anything is in default.
So the HTTP POST on the API side needs to treat the incoming payload as plain text and convert it to JSON. That means I can simply use sendBeacon(url, data). We use the request integrations to set some supplementary data (date, remote IP).
Since sendBeacon doesn’t allow a response, it worked well for fault tolerance. It blindly ignored errors, so if the system was not resilient enough, the actual collection would be impacted, but the client would not.
Processing the data
As stated, the data was dumped into a bucket while the reporting processes were handled. The reporting side needs to happen, but it doesn’t need to happen quickly, i.e. within 30 minutes or any other threshold.
The data is saved in batches, and it's inserted into an SQS queue. A Python process was developed to process the data and pass it into the reporting structures (outside the scope of this article). The data passed on from this included the referring domains, the count of instances, and, if one could be parsed, an affiliate ID, along with the date and a country (the only reason for collecting the source IP).
My initial idea was to simply use EventBridge to start a container running the Python process. That's simple enough for this.
We need to do some other processing, so processing a batch inside a lambda wasn’t really an option. In the absence of that requirement, it would have been a good idea to use a Lambda function to process the data when the bucket raises an SNS notification.
For now, Event Bridge raises a timed event, starts a container on Fargate, and then quits. The system is scoped to allow multiple processors, so pending batches are processed once and logged upstream, so if they need reprocessing, it can be done.
The referring domain is sent to an upstream process for analysis of its content, which then feeds back to the reporting mechanisms so the client can determine problematic websites and prioritise workloads.
The final architecture as a visual
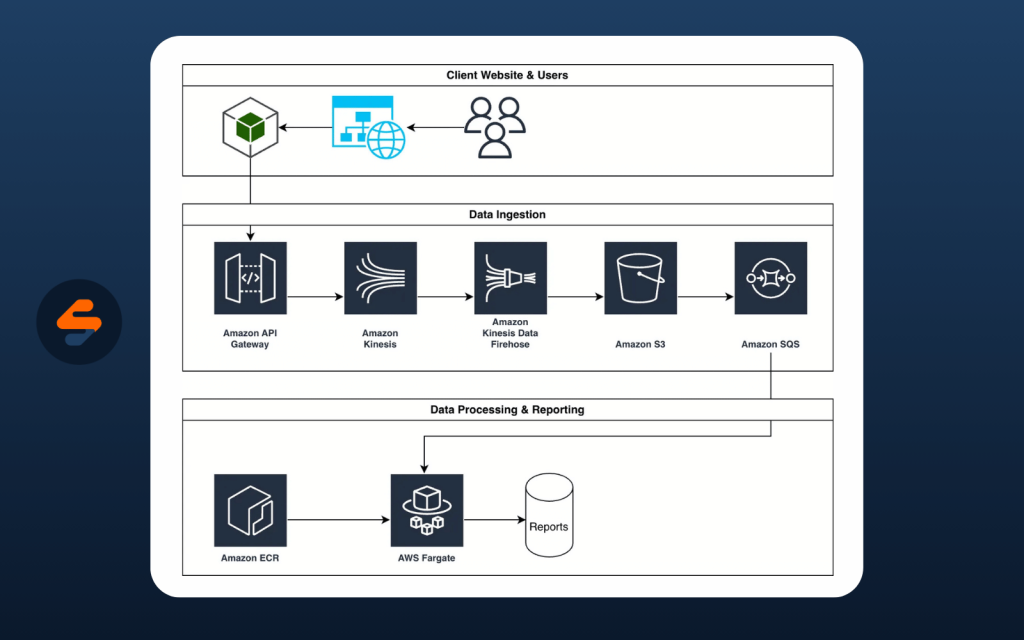
Common Questions
Why decoupled architecture?
When you have processes that are all intertwined, the system can only move as fast as the slowest bit. Decoupling the architecture enabled the system to be burstable. If the client launched a promotion and their visitors doubled, messages would increase in SQS or Firehose might generate larger files, but once the data is collected, processing time is not an important factor.
Why the Fargate Cluster?
Simply, it wasn’t clear how this data was to be reported or actioned upon. The priority initially was to get a list of websites generating traffic, but it then evolved into slightly more complex reporting, including the number of occurrences, dates, and affiliate IDs. This influenced the subsequent process of identifying the most active sources and processing them first.
The Fargate cluster enabled scalable processing when a backlog occurred. The batch files were produced on S3 and then stored in a data store, allowing a processor to claim a batch, process it, and scale horizontally across processors.
Could you reprocess data?
Yes, but the reality is, this isn’t a requirement. Since there is only interest in tracking referring URLs, there is no reason to do so, even though the capability exists. Data is stored by client and date, so reprocessing is very simple.
What about abuse?
It was abused. It’s going to happen. But a couple of steps were taken to minimise the impact. Firstly, if a referrer is already identified,
The impact
The final solution worked because it was fault-tolerant and resilient, and errors did not affect user activity. The client did not involve widespread teams across their business; we just needed them to paste under 15 lines of JavaScript into their website. In the event of a rollback, the client only needed to remove those 15 lines of JavaScript.
Once the data was received, it could be processed in a more leisurely manner.
The short version is that the client is still in business and they’ve solved their immediate regulatory compliance issues. The product has been moved into a monitoring tool and a tracking tool.
They ask their affiliates to disclose websites, but sometimes some don’t; this allows almost immediate discovery of new source sites that can then be monitored for compliance.
The solution ultimately mitigated and reduced their risk and exposure, and satisfied regulators quickly and at an affordable cost.
How's it performing now
The system has since been expanded to a few extra clients and is processing over 200,000,000 page views per month. The system was developed into a fully automated SAAS product in 2026 and continues to provide value for clients.